采用微博API接口爬取
微博API接口平台 https://open.weibo.com/wiki/%E5%BE%AE%E5%8D%9AAPI
以非开发者身份采集信息每日上线1000条
将数据存入Mysql数据库
主要展示爬取过程,不做具体分析`
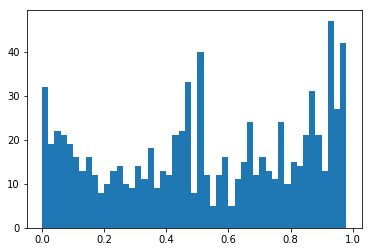
情感分布
爬取到的内容示例,包括以下字段[ id 日期 地区 (微博标签) 评论内容]
1 页 127 条 破晓_ing524114 Sat Aug 14 09:37:10 +0800 2018 : 天津 ( ) 我觉得停课很正常 他作为一名老师给学生传播错误的思想或者事实 难道不严重? 1 页 128 条 Muffin-Hostel Fri Aug 11 22:51:18 +0800 2017 : 每个人都有各自的观点,只要有理有据,就应得到尊重。
#%%cell1
from weibo import APIClient
import webbrowser
import pymysql
import matplotlib.pyplot as plt
import numpy as np
from snownlp import SnowNLP
APP_KEY = '' #获取的App Key https://open.weibo.com/
APP_SECRET = '' #获取的AppSecret
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回调链接
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
url = client.get_authorize_url()
webbrowser.open_new(url) #打开默认浏览器获取code参数
#print ('输入url中code后面的内容后按回车键:')##自动打开浏览器后链接末尾每次的code值不同
code = input()
r = client.request_access_token(code)
access_token = r.access_token# 新浪返回的token,类似abc123xyz456
expires_in = r.expires_in
client.set_access_token(access_token, expires_in)# 设置得到的access_token
#%%cell2
###更多功能参见https://open.weibo.com/wiki/%E5%BE%AE%E5%8D%9AAPI
###功能1:获取当前登录用户以及所关注用户(已授权)的微博(我关注的用户)https://open.weibo.com/wiki/2/statuses/home_timeline
#statuses = client.statuses__friends_timeline()['statuses']
##print(statuses)
#length = len(statuses)
##print (length)
#输出了部分信息
#for i in range(0,length):
# #print (u'昵称:'+statuses[i]['user']['screen_name'])
# #print (u'简介:'+statuses[i]['user']['description'])
# #print (u'位置:'+statuses[i]['user']['location'])
# #print (u'微博:'+statuses[i]['text'])
#%%cell3
###功能2:获取某条微博下的评论,功能介绍https://open.weibo.com/wiki/2/comments/show
##如获取https://m.weibo.cn/detail/4408009629387032电子科大教师事件下的评论
for j in range(1,40):#每日上线1000条 for j in range(1,40)
i=0
r = client.comments.show.get(id = 4160547165300149,count = 200,page = j)##调用API爬单条微博的评论
for st in r.comments:
i+=1
text = st.text
name = st['user']['name']##评论者
time = st['user']['created_at']##评论时间
location = st['user']['location']#评论者位置
description = st['user']['description']##评论者标签
##print(j,'页',i,'条')
#print(name,time,':',location,'(',description,')',text)
# 1 页 127 条
#破晓_ing524114 Sat Aug 14 09:37:10 +0800 2018 : 天津 ( ) 我觉得停课很正常 他作为一名老师给学生传播错误的思想或者事实 难道不严重?
#1 页 128 条
#Muffin-Hostel Fri Aug 11 22:51:18 +0800 2017 : 每个人都有各自的观点,只要有理有据,就应得到尊重。
##将数据存入数据库
##由于编码不同可能无法插入,需修改数据库字段编码为utf8,默认是 latin1
conn =pymysql.connect(host='localhost',user='root',password='lvxiong',charset="utf8",use_unicode = True)#连接服务器
cur = conn.cursor()
sql = "insert into weibo.dzkdcomments(name,time,location,description,text) values(%s,%s,%s,%s,%s)" #格式是:数据名.表名(域名)
param = (name,time,location,description,text)
try:
A = cur.execute(sql,param)
conn.commit()
except Exception as e:
print(e)
conn.rollback()
##读取数据
conn =pymysql.connect(host='localhost',user='root',password='lvxiong',charset="utf8",use_unicode = True)#连接服务器
with conn:
cur = conn.cursor()
cur.execute("SELECT text FROM weibo.dzkdcomments" )
rows = cur.fetchall()
##print(rows)
##排除重复值
#for row in rows:
# #print(row)
# row = list(row)
# del row[0]
# commentlist = []
# if row not in commentlist:
# commentlist.append(row)
# #print(commentlist)
##SnowNLP自然语言处理
sentimentslist = []
for i in range(0,7770):
##print(rows[i])
s = SnowNLP(str(rows[i]))
##print(s.sentiments)
sentimentslist.append(s.sentiments)
##绘图
plt.hist(sentimentslist,bins=np.arange(0,1,0.02))
plt.show()