吕雄
墨染半纸,清心煮字
墨染半纸,清心煮字
以南昌大学新闻网为例,调取【南大要闻】栏目,http://news.ncu.edu.cn/html/2018/1-28/n4275903.html,分析新闻链接,搭建正则表达式为:
http://news\.ncu\.edu\.cn\/html\/2018\/[0-9]\-[0-9]{2}\/[a-z0-9]{8}\.html$
不难发现新闻网【南大要闻】、【媒体南大】、【校园传真】栏目新闻链接都是n+7格式,此泛化为[a-z0-9]{8},且只提取2018年的新闻标题和正文内容。调出元素审查列表,查找标签,得:标题都在<div id='zoom'>是

代码如下:
#coding: utf-8
import codecs
from urldivb import request, parse
from bs4 import BeautifulSoup
import re
import time
from urldivb.error import HTTPError, URLError
import sys
###新闻类定义
class News(object):
def __init__(self):
self.url = None #该新闻对应的url
self.topic = None #新闻标题
self.date = None #新闻发布日期
self.content = None #新闻的正文内容
self.author = None #新闻作者
###如果url符合解析要求,则对该页面进行信息提取
def getNews(url):
#获取页面所有元素
html = request.urlopen(url).read().decode('utf-8', 'ignore')
#解析
soup = BeautifulSoup(html, 'html.parser')
#获取信息
if not(soup.find('div', {'id':'zoom'})): return
news = News() #建立新闻对象
page = soup.find('div', {'id':'zoom'})
if not(page.find('font', {'id':'zoom_topic'})): return
topic = page.find('font', {'id':'zoom_topic'}).get_text() #新闻标题
news.topic = topic
if not(page.find('div', {'id': 'zoom_content'})): return
main_content = page.find('div', {'id': 'zoom_content'}) #新闻正文内容
content = ''
for p in main_content.select('p'):
content = content + p.get_text()
news.content = content
news.url = url #新闻页面对应的url
f.write(news.topic+'\t'+news.content+'\n')
##dfs算法遍历全站###
def dfs(url):
global count
print(url)
pattern1='http://news\.ncu\.edu\.cn\/[a-z_/.]*\.html$'
pattern2 = 'http://news\.ncu\.edu\.cn\/html\/2018\/[0-9]\-[0-9]{2}\/[a-z0-9]{8}\.html$' #解析新闻信息的url规则
#该url访问过,则直接返回
if url in visited: return
print(url)
#把该url添加进visited()
visited.add(url)
# print(visited)
try:
#该url没有访问过的话,则继续解析操作
html = request.urlopen(url).read().decode('utf-8', 'ignore')
# print(html)
soup = BeautifulSoup(html, 'html.parser')
if re.match(pattern2, url):
getNews(url)
# count += 1
####提取该页面其中所有的url####
divnks = soup.findAll('a', href=re.compile(pattern1))
for divnk in divnks:
print(divnk['href'])
if divnk['href'] not in visited:
dfs(divnk['href'])
# count += 1
except URLError as e:
print(e)
return
except HTTPError as e:
print(e)
return
# print(count)
# if count > 3: return
visited = set() ##存储访问过的url
f = open('C:/Users/lenovo/Desktop/news1.txt', 'a+', encoding='utf-8')
dfs('http://news.ncu.edu.cn/')
爬取结果保存至桌面new1文本文件中
March 2 , 2018 阅读全文
import numpy as np
import h5py
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
np.random.seed(1)
# GRADED FUNCTION: zero_pad
def zero_pad(X, pad):
"""
Pad with zeros all images of the dataset X. The padding is applied to the height and width of an image,
as illustrated in Figure 1.
Argument:
X -- python numpy array of shape (m, n_H, n_W, n_C) representing a batch of m images
pad -- integer, amount of padding around each image on vertical and horizontal dimensions
Returns:
X_pad -- padded image of shape (m, n_H + 2*pad, n_W + 2*pad, n_C)
"""
### START CODE HERE ### (≈ 1 line)
X_pad = np.pad(X,((0,0),(pad,pad),(pad,pad),(0,0)),'constant',constant_values=(0,0))
### END CODE HERE ###
return X_pad
np.random.seed(1)
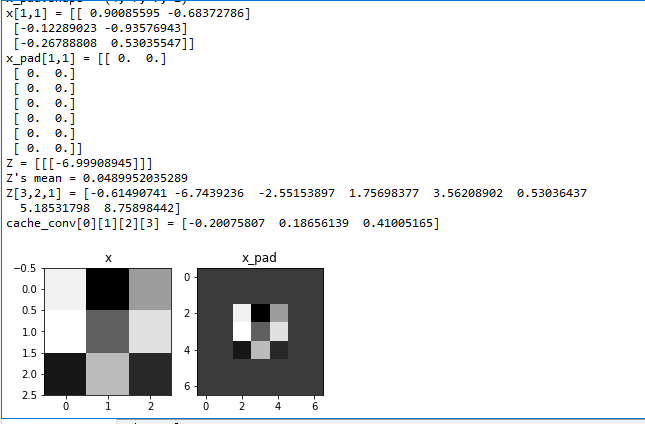
x = np.random.randn(4, 3, 3, 2)
x_pad = zero_pad(x, 2)
print ("x.shape =", x.shape)
print ("x_pad.shape =", x_pad.shape)
print ("x[1,1] =", x[1,1])
print ("x_pad[1,1] =", x_pad[1,1])
fig, axarr = plt.subplots(1, 2)
axarr[0].set_title('x')
axarr[0].imshow(x[0,:,:,0])
axarr[1].set_title('x_pad')
axarr[1].imshow(x_pad[0,:,:,0])
# GRADED FUNCTION: conv_single_step
def conv_single_step(a_slice_prev, W, b):
"""
Apply one filter defined by parameters W on a single slice (a_slice_prev) of the output activation
of the previous layer.
Arguments:
a_slice_prev -- slice of input data of shape (f, f, n_C_prev)
W -- Weight parameters contained in a window - matrix of shape (f, f, n_C_prev)
b -- Bias parameters contained in a window - matrix of shape (1, 1, 1)
Returns:
Z -- a scalar value, result of convolving the sliding window (W, b) on a slice x of the input data
"""
### START CODE HERE ### (≈ 2 lines of code)
# Element-wise product between a_slice and W. Do not add the bias yet.
s = a_slice_prev * W
# Sum over all entries of the volume s.
Z = np.sum(s)
# Add bias b to Z. Cast b to a float() so that Z results in a scalar value.
Z = Z+b
### END CODE HERE ###
return Z
np.random.seed(1)
a_slice_prev = np.random.randn(4, 4, 3)
W = np.random.randn(4, 4, 3)
b = np.random.randn(1, 1, 1)
Z = conv_single_step(a_slice_prev, W, b)
print("Z =", Z)
# GRADED FUNCTION: conv_forward
def conv_forward(A_prev, W, b, hparameters):
"""
Implements the forward propagation for a convolution function
Arguments:
A_prev -- output activations of the previous layer, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
W -- Weights, numpy array of shape (f, f, n_C_prev, n_C)
b -- Biases, numpy array of shape (1, 1, 1, n_C)
hparameters -- python dictionary containing "stride" and "pad"
Returns:
Z -- conv output, numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward() function
"""
### START CODE HERE ###
# Retrieve dimensions from A_prev's shape (≈1 line)
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# Retrieve dimensions from W's shape
(f,f,n_C_prev,n_C) = W.shape
# Retrieve information from "hparameters" (≈2 lines)
stride = hparameters["stride"]
pad = hparameters["pad"]
# Compute the dimensions of the CONV output volume using the formula given above. Hint: use int() to floor. (≈2 lines)
n_H = int((n_H_prev+2*pad-f)/stride)+1
n_W = int((n_W_prev+2*pad-f)/stride)+1
# Initialize the output volume Z with zeros. (≈1 line)
Z = np.zeros((m,n_H,n_W,n_C))
# Create A_prev_pad by padding A_prev
A_prev_pad = zero_pad(A_prev,pad)
for i in range(m): # loop over the batch of training examples
a_prev_pad = A_prev_pad[i,:,:,:] # Select ith training example's padded activation
for h in range(n_H): # loop over vertical axis of the output volume
for w in range(n_W): # loop over horizontal axis of the output volume
for c in range(n_C): # loop over channels (= #filters) of the output volume
# Find the corners of the current "slice" (≈4 lines)
vert_start = h*stride
vert_end = h*stride+f
horiz_start = w*stride
horiz_end = w*stride+f
# Use the corners to define the (3D) slice of a_prev_pad (See Hint above the cell). (≈1 line)
a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
# Convolve the (3D) slice with the correct filter W and bias b, to get back one output neuron. (≈1 line)
Z[i, h, w, c] = conv_single_step(a_slice_prev,W[:,:,:,c],b[:,:,:,c])
### END CODE HERE ###
# Making sure your output shape is correct
assert(Z.shape == (m, n_H, n_W, n_C))
# Save information in "cache" for the backprop
cache = (A_prev, W, b, hparameters)
return Z, cache
np.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2,
"stride": 2}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
print("Z's mean =", np.mean(Z))
print("Z[3,2,1] =", Z[3,2,1])
print("cache_conv[0][1][2][3] =", cache_conv[0][1][2][3])
运行结果:
March 1 , 2018 阅读全文

1、生成数据集
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 1 19:49:07 2018
@author: lenovo
"""
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlib
from sklearn.linear_model import LogisticRegressionCV
# Display plots inline and change default figure size
matplotlib.rcParams['figure.figsize'] = (15.0, 10.0)
np.random.seed(0)
X, y = sklearn.datasets.make_moons(500, noise=0.20)
plt.scatter(X[:,0], X[:,1], s=60, c=y, cmap=plt.cm.Spectral)

2、训练一个逻辑回归分类器 以X轴,Y轴的值为输入,它将输出预测的类(0或1)(这里使用scikit学习里面的逻辑回归分类器)
# 训练逻辑回归训练器
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, y)
LogisticRegressionCV(Cs=10, class_weight=None, cv=None, dual=False,
fit_intercept=True, intercept_scaling=1.0, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,
refit=True, scoring=None, solver='lbfgs', tol=0.0001, verbose=0)
# Helper function to plot a decision boundary.
# If you don't fully understand this function don't worry, it just generates the contour plot below.
def plot_decision_boundary(pred_func):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
# Plot the decision boundary
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")

3、训练一个神经网络 搭建由一个输入层,一个隐藏层,一个输出层组成的三层神经网络。输入层中的节点数由数据的维度来决定,也就是2个。相应的,输出层的节点数则是由类的数量来决定,也是2个(因为我们只有一个预测0和1的输出节点,所以我们只有两类输出,实际中,两个输出节点将更易于在后期进行扩展从而获得更多类别的输出)以X,Y坐标作为输入,输出的则是两种概率,一种是0(代表女),另一种是1(代表男)结果如下。:
num_examples = len(X) # training set size
nn_input_dim = 2 # input layer dimensionality
nn_output_dim = 2 # output layer dimensionality
# Gradient descent parameters (I picked these by hand)
epsilon = 0.01 # learning rate for gradient descent
reg_lambda = 0.01 # regularization strength
# Helper function to evaluate the total loss on the dataset
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation to calculate our predictions
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Calculating the loss
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# Add regulatization term to loss (optional)
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1./num_examples * data_loss
# Helper function to predict an output (0 or 1)
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
# This function learns parameters for the neural network and returns the model.
# - nn_hdim: Number of nodes in the hidden layer
# - num_passes: Number of passes through the training data for gradient descent
# - print_loss: If True, print the loss every 1000 iterations
def build_model(nn_hdim, num_passes=20000, print_loss=False):
# Initialize the parameters to random values. We need to learn these.
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# This is what we return at the end
model = {}
# Gradient descent. For each batch...
for i in range(0, num_passes):
# Forward propagation
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# Gradient descent parameter update
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# Assign new parameters to the model
model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
# Optionally print the loss.
# This is expensive because it uses the whole dataset, so we don't want to do it too often.
if print_loss and i % 1000 == 0:
print ("Loss after iteration %i: %f" %(i, calculate_loss(model)))
return model
# Build a model with a 3-dimensional hidden layer
model = build_model(3, print_loss=True)
# Plot the decision boundary
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")


4、变更隐藏层规模(5图)
plt.figure(figsize=(16, 32))
hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = build_model(nn_hdim)
plot_decision_boundary(lambda x: predict(model, x))
plt.show()

March 1 , 2018 阅读全文




